Software is for the user. It is not for the Software Engineers who develop it. In the end, software will succeed or fail to meet user needs. The user is the arbiter of software’s fate. Oddly though, many software developers tend to resent their users. The users are prone to strange behaviors. Sometimes they can even come across as whinny children to jaded developers. But we must do away with this flawed way of thinking. We must act as humble stewards, gentle of heart, and eager to please.
Users are the life blood of a software product. Without them, the product will fail. As a result their needs are paramount, and must be address to the best of our abilities. If this is the case, then why are developers so often frustrated by their users? Remember we are fluent in the machine tongue. Generally speaking, users aren’t. Sure they can use the machines, to a limited degree. But they don’t understand them like we do.
Imagine you are in a foreign country. The only way to get your work done is to cajole a lumbering beast into action for you. Without understanding the beast’s language, even simple tasks could be infuriating. Users who are less familiar with software might feel the same. Only remember that we specialize software to particular tasks. As a result users need to learn, remember and use a variety of these ‘beasts’ to get their work done. Also remember, they are being evaluated by their ability to get work done, using your software.
And so scared, frustrated, and feeling impotent, they turn to us. They wonder why their actions did not work. They ask for strange features or work-flows. All these feeling arise because they don’t understand their tools. Sure we could ‘educate them’. But if the way to use a tool is less than obvious, or they only use it seldom, then you can expect them to forget. Not to mention, you have to convince them to take the time to get trained, rather than working. Even we don’t feel comfortable trading training time for working time. So why should we ask that of them?
Two paths remain to us. We can tell the user’s they are wrong and constantly bicker with them, trying to explain the proper way. Or we can choose to listen. The way we thought was obvious is not. They need more help, because the grammar of machines is difficult. I would call this path ‘Stewardship’. We have to think of the code as belonging to the users, not to us. In so doing, it becomes clear what choices we need to make. If the code is for the user, then their needs overrule ours. If they aren’t fluent, we must may the software more approachable.
We are like gardeners. The land we tend is not our own, but still we make it bloom with brilliant flowers. We cherish the blossoms, and suffer when they are trodden upon. But the garden is not for us. Imagine if the gardener chased off the owner with a spade when he ask for a new row of lilies. The gardener would be marched off and a new one brought in to replace him. This is not an exact analogy, since users pick their software. They might just avoid a certain gardener altogether.
If instead, we are gentle and approachable, we could better tend our gardens. If no one ever walks our garden paths, then we put to waste all the love and beauty to garden contains. Software without users, despite its brilliant design, and delicious complexity, is dead. If we want vibrant, living software we must serve our users. We cannot lord our understanding over them, but must instead steward the code for them. With gentle hearts, we can learn their needs, and make the garden they need. In the process we may discover an even greater beauty.



 This weakness results from the License Checking each ObjectType for its data type. This could be easily fixed if the License were to use a data type to Permissions dictionary rather than a simple list. However time has not yet been allocated to for this change, and the solution was not discovered until after the project was determined to be complete.
This weakness results from the License Checking each ObjectType for its data type. This could be easily fixed if the License were to use a data type to Permissions dictionary rather than a simple list. However time has not yet been allocated to for this change, and the solution was not discovered until after the project was determined to be complete.
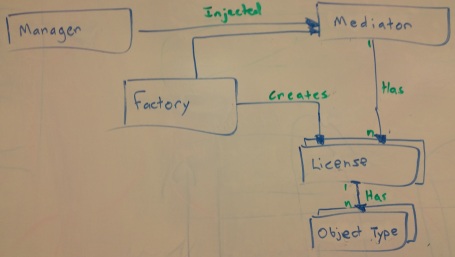

 For example, in order to determine if a user is allowed to load a given data type from the database, the data manager would first query the License Manager for Feature Licenses X, Y, and Z. Then if the user had X or Y, but not Z they would be allowed to proceed to loading. If they have Feature X they loaded a particular subset of the data, and if they have Feature Y they loaded a different one.
For example, in order to determine if a user is allowed to load a given data type from the database, the data manager would first query the License Manager for Feature Licenses X, Y, and Z. Then if the user had X or Y, but not Z they would be allowed to proceed to loading. If they have Feature X they loaded a particular subset of the data, and if they have Feature Y they loaded a different one.